

大豆分離蛋白具有功能性、營養性和經濟性,廣泛應用于食品及其他行業中,大豆分離蛋白酶解過程會引入許多不良味道,特別是苦味。目前苦味評價主要采用傳統的感官評價,但感官評價存在主觀性,對準確度和重復性等方面的把握有所欠缺。近年來,電子舌作為一種能快速檢測味覺品質的新技術,可以對復雜樣品最基本的酸、甜、苦、辣、咸味覺評價指標進行快速的味覺檢測分析。
本文采用法國Alpha MOS公司Astree電子舌采集配方溶液信號,利用PCA和DFA進行定性分析,結合偏最小二乘法和RBF神經網絡建立苦味定量預測模型。
大豆分離蛋白、堿性蛋白酶、奎寧。
配制不同質量濃度(1g/mL、2g/mL、4g/mL、8g/mL、16g/mL、32g/mL)的奎寧溶液作為苦味標準液,大豆分離蛋白配方見表1。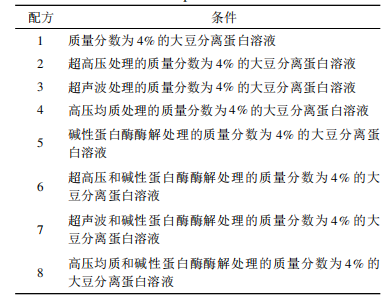 儀器與方法
儀器與方法
使用法國Alpha MOS公司Astree電子舌采集配方的味覺信息。它由一個16位自動進樣器、安裝在Ag/AgCl參比電極上的7根具有交叉敏感性的傳感器陣列(ZZ、JE、BB、CA、GA、HA和JB)、信號采集模塊以及模式識別系統組成。電子舌模擬人類的感覺器官舌頭對待測樣品進行分析、識別和判斷。每根傳感器對不同樣品吸附溶液分子的靈敏度不同,表現出不同的電位變化,根據電位變化分析溶液的味覺特性。
試驗開始前,為了使結果更準確,需要對電子舌進行調試,主要包括活化、初始化、校準和診斷等環節。試驗開始時,將待測液倒入電子舌專用燒杯中,按照待測液-清洗液-待測液的順序交替擺放在電子舌自動進樣器上,樣品數據采集時間默認為120s,每種樣品重復采集10次,為了得到穩定和準確的試驗數據,同時也為了減少誤差,去除第1次和最后1次采集到的數據,用中間8個數據進行后續處理。
為了比較8種配方的苦味程度,選取20名對苦味敏感的感官評價員,對8種配方進行品嘗,根據表2的評價標準進行評價。配方1-配方8的苦味得分分別為3.7、3.8、3.9、4.0、4.1、4.1、4.3、4.4。由評分結果可知,8種配方苦味差異不大,苦味均可以接受,8種配方苦味得分近似呈線性分布。 2、傳感器的選擇
2、傳感器的選擇
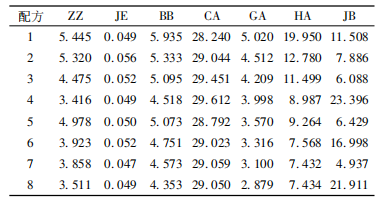
使用Astree電子舌采集樣品味覺信息,圖1為7根傳感器對配方1的響應強度。由圖1可見,傳感器JE的電壓響應強度最高,ZZ與BB的電壓響應強度接近,HA的電壓響應強度最低,最不敏感。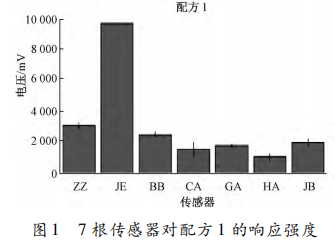 表3為7根傳感器在8種配方中的相對標準偏差。由表3可知,傳感器JE、ZZ、BB、GA對8種配方的相對標準偏差均小于6%,傳感器CA、HA、JB的相對標準偏差6%<RSD<30%。表明傳感器CA、HA、JB會影響試驗結果,造成較大偏差。剔除判別能力較弱的傳感器,選擇判別能力強的傳感器,以增強試驗的準確性。故選用傳感器JE、ZZ、BB和GA分析8種配方的味覺信息。
表3為7根傳感器在8種配方中的相對標準偏差。由表3可知,傳感器JE、ZZ、BB、GA對8種配方的相對標準偏差均小于6%,傳感器CA、HA、JB的相對標準偏差6%<RSD<30%。表明傳感器CA、HA、JB會影響試驗結果,造成較大偏差。剔除判別能力較弱的傳感器,選擇判別能力強的傳感器,以增強試驗的準確性。故選用傳感器JE、ZZ、BB和GA分析8種配方的味覺信息。
3、主成分分析和判別因子分析
主成分分析(PCA)是一種降低數據集維數的多元統計方法,它在不丟失任何信息的前提下,對采集到的數據進行降維處理和數據轉換,據此把多個相關性很高的變量歸結為幾個不相干變量或相關性很低的變量。主成分分析散點圖上的散點代表樣品,散點之間的距離代表樣品間的差異性與親疏性,主成分貢獻率越大,代表包含更多數據信息。
判別因子分析(DFA)是一種通過重新組合原始變量信息來優化區分的分類技術,它根據相關性大小把數據分組,且不改變原有變量,使不同類數據組間距離最大的同時,保證同類數據組內差異最小,使各個組間的重心距離最大。
選用奎寧作為苦味標準液對8種配方進行試驗,所得結果分別用PCA和DFA進行分析。
選擇傳感器JE、ZZ、BB、GA,PCA和DFA分析結果見圖3。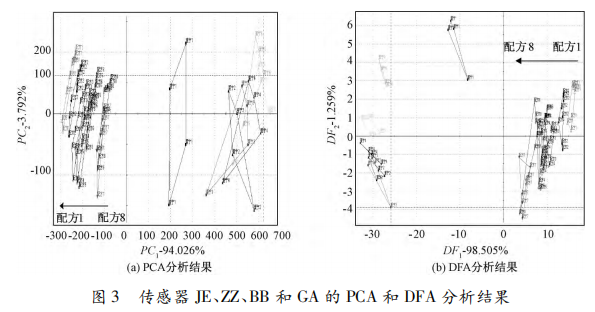 由圖3可知,主成分PC1、PC2貢獻率分別為94.026%和3.792%,判別因子DF1、DF2貢獻率分別為98.505%和1.259%,總貢獻率近似為100%。奎寧溶液與配方溶液的落點分居于y軸兩側,表明配方溶液與奎寧溶液區分度高。奎寧溶液與配方溶液組間距離較遠,表明8種配方溶液苦味不明顯。8種配方溶液組內離散程度較小,表明各配方之間苦味差異性小。PCA、DFA顯示一致的苦味評價結果。因此,PCA和DFA均可鑒別配方的苦味程度。
由圖3可知,主成分PC1、PC2貢獻率分別為94.026%和3.792%,判別因子DF1、DF2貢獻率分別為98.505%和1.259%,總貢獻率近似為100%。奎寧溶液與配方溶液的落點分居于y軸兩側,表明配方溶液與奎寧溶液區分度高。奎寧溶液與配方溶液組間距離較遠,表明8種配方溶液苦味不明顯。8種配方溶液組內離散程度較小,表明各配方之間苦味差異性小。PCA、DFA顯示一致的苦味評價結果。因此,PCA和DFA均可鑒別配方的苦味程度。
4、PLS建模及預測
建立PLS大豆分離蛋白苦味預測模型,以4根優化后傳感器電壓響應值作為自變量,以感官評分值作為因變量構建PLS模型。得回歸方程:
y=66.6953-0.0041s1-0.0053s2+0.0004s3-0.0001s4,
式中:y為電子舌苦味預測值;s1、s2、s3、s4分別為傳感器ZZ、JE、BB、GA電壓響應值。
在所建立的偏最小二乘模型中,P(P=0.000)<0.05,表明此模型的回歸方程具有顯著意義。以4根優化后傳感器電壓響應值構建PLS為0.969,RMSE為0.035,實際值與預測值有較好的相關性,預測效果較好。
5、RBF建模及預測
本次試驗重疊系數選取范圍為1~3,隱含層節點數選取范圍為4~15。建立兩個RBF神經網絡模型,其中建模集有32個樣本,預測集有32個樣本。輸入層節點數都為4,分別對應4根傳感器電壓響應值和前4個PC值,隱含層節點通過自身學習確定最優節點數,輸出層輸出配方的苦味得分。預測結果表明,隨著重疊系數的增加,建模集與預測集的RMSE逐漸減小,因此最終確定重疊系數為3。隨著隱含層節點數的增加,RMSE逐漸減小,但隱含層節點數增加到一定值之后,RMSE逐漸增大,由此確定最佳隱含層R節點數為9。在4-9-1結構中,4根優化后傳感器電壓響應值預測集的RMSE和分別為0.010和0.987,前4個PC預測集的RMSE和R分別為0.007、0.913。RMSE小于PLS預測模型的0.035、0.093,R均大于PLS預測模型的0.969、0.334,說明4根傳感器電壓響應值與前4個PC作為輸入參數建立的RBF預測模型預測值更接近真實值,預測效果較好。
參考文獻:蘆建超,惠延波,胡曉利,布冠好.基于電子舌的大豆分離蛋白苦味分析與評價技術研究[J].河南工業大學學報(自然科學版),2019,40(06):65-69+79.DOI:10.16433/j.cnki.issn1673-2383.2019.06.011.
提醒:文章僅供參考,如有不當,歡迎留言指正和交流。且讀者不應該在缺乏具體的專業建議的情況下,擅自根據文章內容采取行動,因此導致的損失,本運營方不負責。如文章涉及侵權或不愿我平臺發布,請聯系處理。 本文采用法國Alpha MOS公司Astree電子舌采集配方溶液信號,利用PCA和DFA進行定性分析,結合偏最小二乘法和RBF神經網絡建立苦味定量預測模型。
一、材料與方法
試驗材料大豆分離蛋白、堿性蛋白酶、奎寧。
配制不同質量濃度(1g/mL、2g/mL、4g/mL、8g/mL、16g/mL、32g/mL)的奎寧溶液作為苦味標準液,大豆分離蛋白配方見表1。
表1 試驗配方
使用法國Alpha MOS公司Astree電子舌采集配方的味覺信息。它由一個16位自動進樣器、安裝在Ag/AgCl參比電極上的7根具有交叉敏感性的傳感器陣列(ZZ、JE、BB、CA、GA、HA和JB)、信號采集模塊以及模式識別系統組成。電子舌模擬人類的感覺器官舌頭對待測樣品進行分析、識別和判斷。每根傳感器對不同樣品吸附溶液分子的靈敏度不同,表現出不同的電位變化,根據電位變化分析溶液的味覺特性。
試驗開始前,為了使結果更準確,需要對電子舌進行調試,主要包括活化、初始化、校準和診斷等環節。試驗開始時,將待測液倒入電子舌專用燒杯中,按照待測液-清洗液-待測液的順序交替擺放在電子舌自動進樣器上,樣品數據采集時間默認為120s,每種樣品重復采集10次,為了得到穩定和準確的試驗數據,同時也為了減少誤差,去除第1次和最后1次采集到的數據,用中間8個數據進行后續處理。
二、結果與分析
1、傳統感官評價為了比較8種配方的苦味程度,選取20名對苦味敏感的感官評價員,對8種配方進行品嘗,根據表2的評價標準進行評價。配方1-配方8的苦味得分分別為3.7、3.8、3.9、4.0、4.1、4.1、4.3、4.4。由評分結果可知,8種配方苦味差異不大,苦味均可以接受,8種配方苦味得分近似呈線性分布。
表2 苦味評價標準
使用Astree電子舌采集樣品味覺信息,圖1為7根傳感器對配方1的響應強度。由圖1可見,傳感器JE的電壓響應強度最高,ZZ與BB的電壓響應強度接近,HA的電壓響應強度最低,最不敏感。
表3 7根傳感器在8種配方中的相對標準偏差
3、主成分分析和判別因子分析
主成分分析(PCA)是一種降低數據集維數的多元統計方法,它在不丟失任何信息的前提下,對采集到的數據進行降維處理和數據轉換,據此把多個相關性很高的變量歸結為幾個不相干變量或相關性很低的變量。主成分分析散點圖上的散點代表樣品,散點之間的距離代表樣品間的差異性與親疏性,主成分貢獻率越大,代表包含更多數據信息。
判別因子分析(DFA)是一種通過重新組合原始變量信息來優化區分的分類技術,它根據相關性大小把數據分組,且不改變原有變量,使不同類數據組間距離最大的同時,保證同類數據組內差異最小,使各個組間的重心距離最大。
選用奎寧作為苦味標準液對8種配方進行試驗,所得結果分別用PCA和DFA進行分析。
選擇傳感器JE、ZZ、BB、GA,PCA和DFA分析結果見圖3。
4、PLS建模及預測
建立PLS大豆分離蛋白苦味預測模型,以4根優化后傳感器電壓響應值作為自變量,以感官評分值作為因變量構建PLS模型。得回歸方程:
y=66.6953-0.0041s1-0.0053s2+0.0004s3-0.0001s4,
式中:y為電子舌苦味預測值;s1、s2、s3、s4分別為傳感器ZZ、JE、BB、GA電壓響應值。
在所建立的偏最小二乘模型中,P(P=0.000)<0.05,表明此模型的回歸方程具有顯著意義。以4根優化后傳感器電壓響應值構建PLS為0.969,RMSE為0.035,實際值與預測值有較好的相關性,預測效果較好。
5、RBF建模及預測
本次試驗重疊系數選取范圍為1~3,隱含層節點數選取范圍為4~15。建立兩個RBF神經網絡模型,其中建模集有32個樣本,預測集有32個樣本。輸入層節點數都為4,分別對應4根傳感器電壓響應值和前4個PC值,隱含層節點通過自身學習確定最優節點數,輸出層輸出配方的苦味得分。預測結果表明,隨著重疊系數的增加,建模集與預測集的RMSE逐漸減小,因此最終確定重疊系數為3。隨著隱含層節點數的增加,RMSE逐漸減小,但隱含層節點數增加到一定值之后,RMSE逐漸增大,由此確定最佳隱含層R節點數為9。在4-9-1結構中,4根優化后傳感器電壓響應值預測集的RMSE和分別為0.010和0.987,前4個PC預測集的RMSE和R分別為0.007、0.913。RMSE小于PLS預測模型的0.035、0.093,R均大于PLS預測模型的0.969、0.334,說明4根傳感器電壓響應值與前4個PC作為輸入參數建立的RBF預測模型預測值更接近真實值,預測效果較好。
三、結論
本文采用法國Astree電子舌對8種不同條件下大豆分離蛋白的苦味進行分析,采用主成分分析、判別因子分析、偏最小二乘法和RBF神經網絡對采集到的數據進行分析。結果表明,PCA與DFA顯示的結果一致,均可鑒別配方的苦味程度;經超聲波、超高壓、高壓均質、酶解處理的大豆分離蛋白苦味相近,經超聲波、超高壓、高壓均質處理酶解的大豆分離蛋白苦味程度較高,勉強可以接受;RBF神經網絡預測模型的預測效果比PLS預測模型的預測效果好,預測結果與感官評價得分結果一致。參考文獻:蘆建超,惠延波,胡曉利,布冠好.基于電子舌的大豆分離蛋白苦味分析與評價技術研究[J].河南工業大學學報(自然科學版),2019,40(06):65-69+79.DOI:10.16433/j.cnki.issn1673-2383.2019.06.011.



